
| Futures |
||
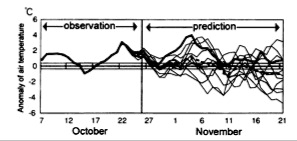
Since computing power is such a key determinant of forecasting ability, it is worthwhile to discuss the likely future of supercomputers. There is currently a lot of interest in parallel processing (supercomputers made of hundreds or thousands of regular processors) because it allows you to build faster computers without new integrated circuit technology – possibly bypassing Moore’s law. However, there are limitations to how far parallel architectures can be taken. “Grid” type problems like atmospheric modeling seem like a good application of multiple processors because separate calculations have to be done at each time step for each parcel in the grid. However, the connected nature of the system means that each parcel also has to share its results with all neighboring parcels at each time step. This slows down the computation considerably, because the processors waste so much time waiting for data to arrive. Attempts to alter the code to remove these lag issues also tend to distort the physics so much that the models become unusable.[58] The choices ahead therefore lie mainly in tradeoffs over how to allocate precious computing time. For instance, more detailed resolutions can provide more precise forecasts over a small area, while less detailed global models can provide better long-range forecasts. Thus one technique is to “nest” small, high-resolution models in larger, lower resolution models. The Japanese Meteorological Agency’s model includes a global, regional, and “mesoscale” level. At certain time steps the levels exchange data, extrapolating where necessary to accommodate different grid sizes and time steps.[59] Similarly, new local high-resolution (1 km square) forecasting services in the U.S. make their predictions by nesting data from densely situated sensors into the rougher grid provided by large government-produced models.[60] A recent study even separated different nest levels of a model onto two supercomputers many miles apart, and successfully ran the model with communication occurring over a high-speed satellite link – giving some hope to the possibility of further distributing the computing load.[61] Another method of forecasting called “ensemble forecasting” has become viable in the last decade and has several important implications. The ensemble technique requires performing a given forecast many times, each based on slightly perturbed initial conditions within the range of error of the observed data. The chaotic nature of the atmosphere means that after a while the forecasts diverge significantly (figure 8). But because the most uncertain aspects vary the most widely, the average of this data turns out to provide better forecasts than any individual run.[62] Also, statistical analyses of the differences between runs allows forecasters to assign probabilities to their forecasts – the basis of a “70% chance of rain”. Such “probability forecasts” are extremely valuable to a wide range of companies for use in expected value calculations (such as the expected cost of various shipping routes). They might also be used in the future for “adaptive observations”, where extra sensors are quickly deployed or satellites aimed to improve the forecasts for areas exhibiting a high degree of uncertainty.[63]
Figure 8: Chaos in action: the divergence of predictions in an ensemble system (light solid lines). The dotted line shows the average of each run, and the dark solid line shows what actually happened.[64] It also turns out that because each forecast in an ensemble is calculated separately from the others, the technique does allow for efficient use of parallel processing.[65] This suggests that the majority of new computing power will go into making ensemble forecasts, both with varied initial conditions and varied model details.[66] It is also especially good news for long-range climate models, which are based on taking the average of numerous simulation runs in order to remove the “noise” caused by individual weather event possibilities while leaving longer-term trends intact.[67] More on this topic is interesting but outside the scope of this paper. In the far future, fundamentally new computing technologies may emerge that do finally affect Moore’s law and thus the scope of weather forecasting. For instance, if computers could somehow solve nonlinear differential equations directly, they might overcome the current fundamental barrier between the continuous nature of physics and the discrete nature of computing.[68] But this is pure speculation.
Footnotes
|
||